NVIDIA CUDA
Массивно-параллельные вычисления на GPU
архитектура и программная среда CUDA
Лекция 4
Оптимизация
Created by Vladimir Kuznetsov / @grandrust
Содержание
- Объединение запросов (Memory coalescing)
- Разделяемая память (Shared memory)
- Оптимизация работы с разделяемой памятью
- Банк-конфликты
Warp
Каждый блок выполняется 32-нитевым группами
- Архитерктурное решение, не является частью программной модели CUDA
- Warp'ы планируются SM
- Нити в Warp'e выполняются в SIMD
- Будующие GPUs, возможно, будут иметь другое количество нитей в Warp'е
Warp Задача
Пусть 3 блока назначены на SM. В каждом блоке 256 нитей.
Сколько warp'ов в SM
- Каждый блок разбивается на 256/32 = 8 Warp'ов
- Всего на SM 8 * 3 = 24 Warp'ов
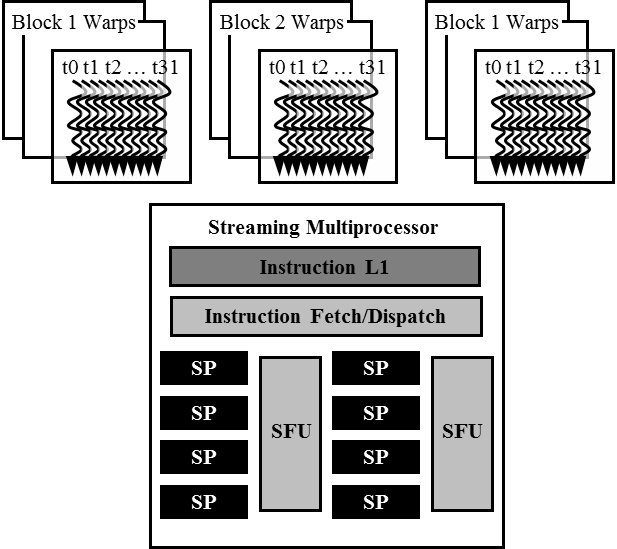
Объединение запросов к памяти
(DRAM Burst)

- Адресное пространство разбито на burst секции
-
- Вне зависимости от области данных, получение данных осуществляется целой секцией
- На практике, DRAM = 4GB, sizeof(burst section) = 128B
Memory Coalescing
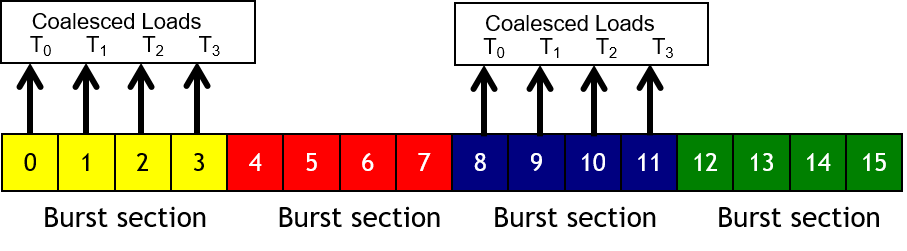
- Если все нити warp'а обращаются к одной burst секции
- В противном случае возможно вплоть до 16 запросов
Un-coalesced доступ
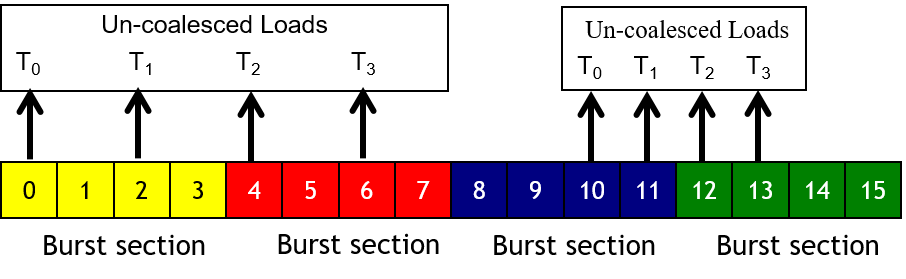
- Когда осуществляется доступ за пределами burst секции(й)
- Как результат, присутствуют данные, неиспользуемые нитями
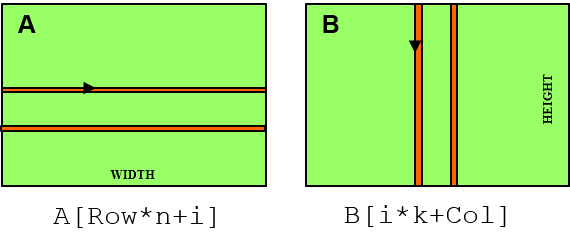
A 2D C Array in Linear Memory Space
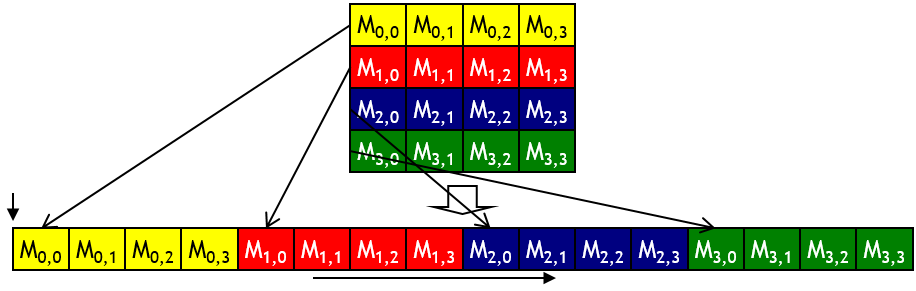
Разделяемая память. Банки
-
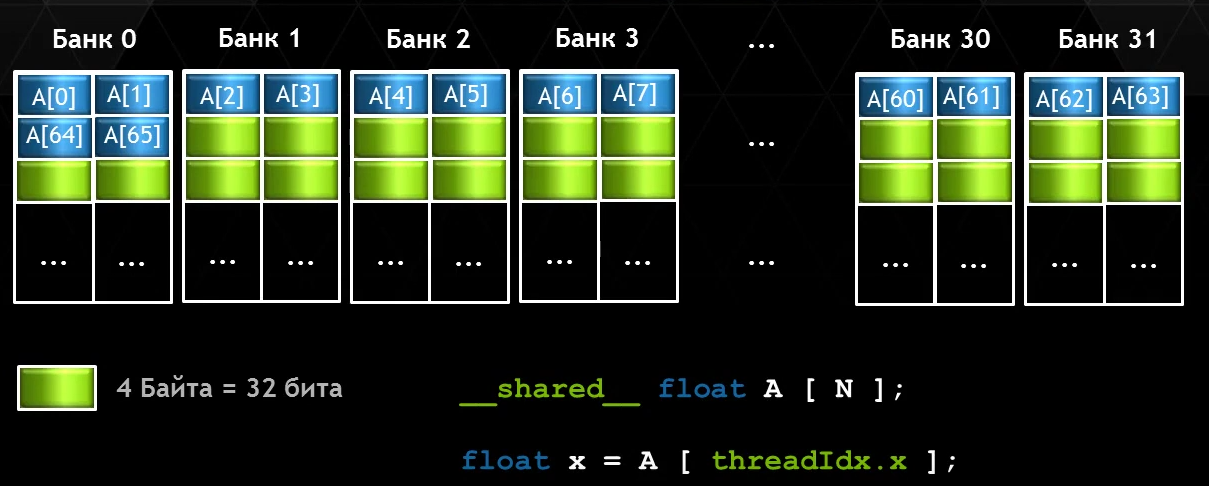
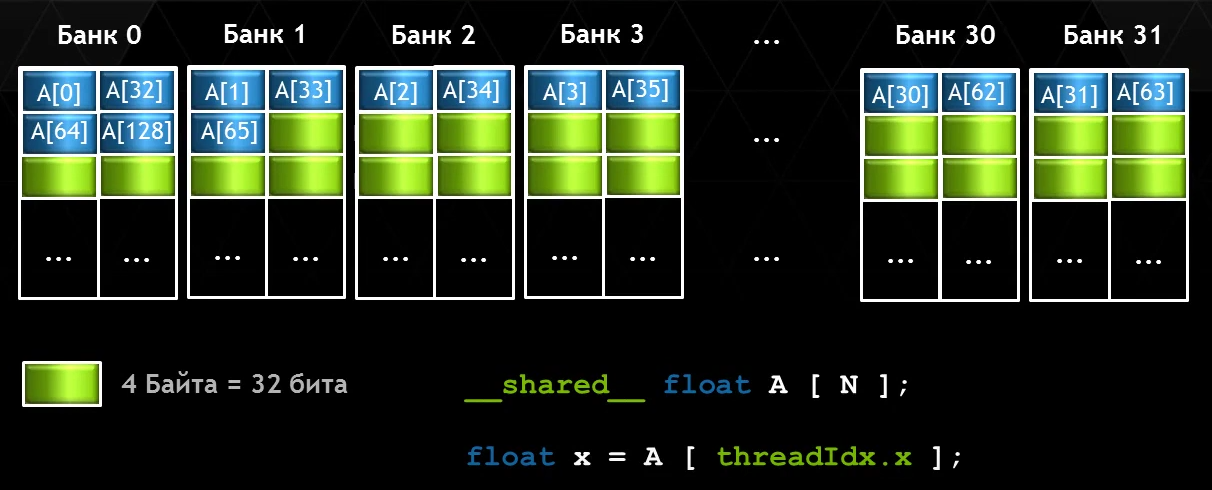
32 банка шириной 8 байт
- Пропускная способность 8 байт за такт SM
- Warp считывает 256 байт за такт SM
-
2 режима:
- 4-байтовый cudaSharedMemBankSizeFourByte (default)
- 8-байтовый cudaSharedMemBankSizeEightByte
- Для установки режима cudaDeviceSetSharedMemConfig()
8-байтовый режим доступа
4-байтовый режим доступа
Банк конфликты
(CC 3.x)
- Возникают:
- Две или более нитей одного Warp'а обращаются к разным 8-байтовым словам, лежащем в одном банке
- Банк-конфликт имеет порядок N, когда конфликтуют N нитей одного Warp'а
-
Отсутствуют:
- Разные нити Warp'а обращаются к одному слову
- Разные нити Warp'а обращаются к различным байтам одного и того же слова
Отсутствие конфликтов

Отсутствие конфликтов
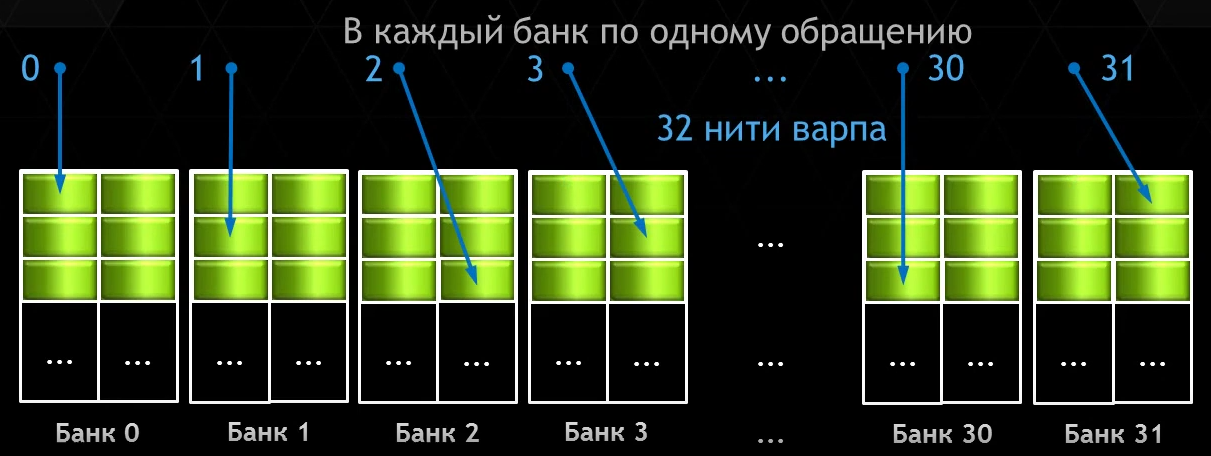
Отсутствие конфликтов
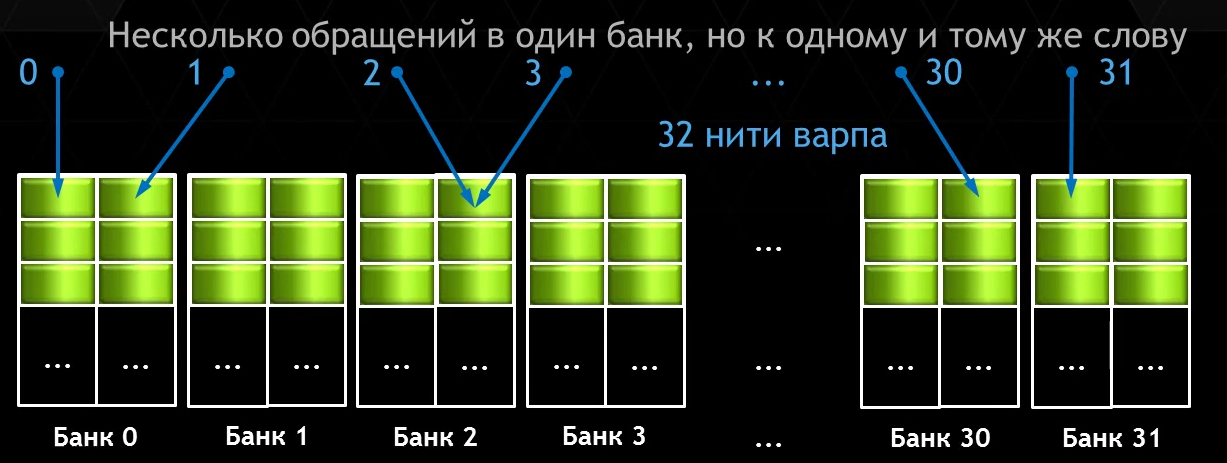
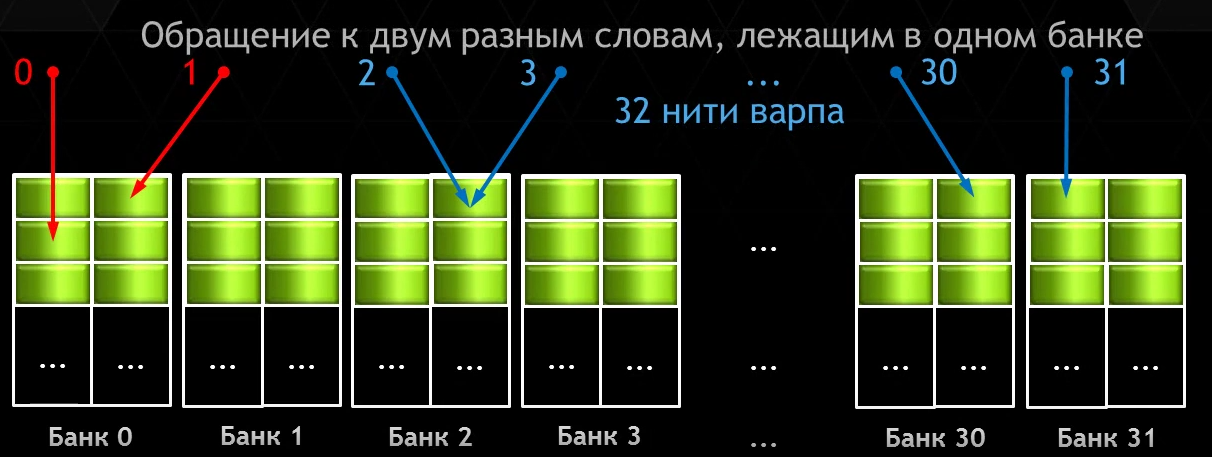
Банк конфликт 2-го порядка
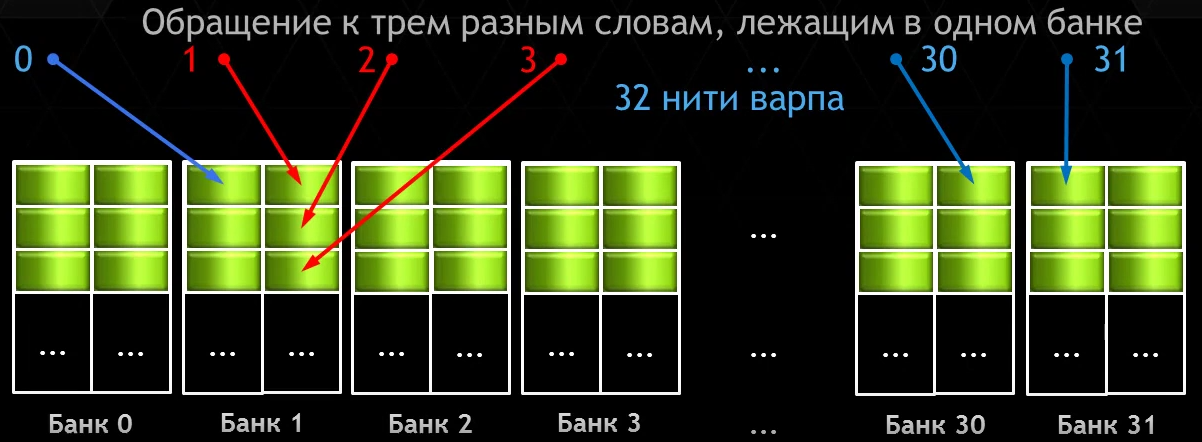
Банк конфликт 3-го порядка
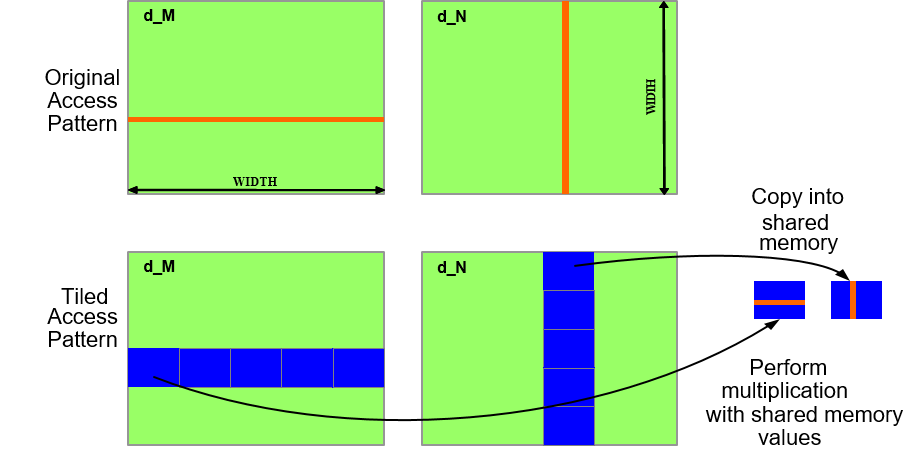
Лабораторная работа
Умножение матриц
N x N = 2048 * 2048
BLOCK_SIZE = 32
(tx, ty) - (32, 32) - размерность block'a
(bx, by) - (?, ?) - размерность grid'a
Простой вариант
Используя shared memory
Вопросы
- Сравнить производительность
- Coalescing?
- Как можно еще улучшить?