NVIDIA CUDA
Массивно-параллельные вычисления на GPU
архитектура и программная среда CUDA
Лекция 3
Работа с памятью
Created by Vladimir Kuznetsov / @grandrust
Содержание
- Типы памяти
- Единая система памяти (Unified Memory)
- Pinned memory
- CUDA streams
Типы памяти
- Регистровая (register)
- Локальная (local)
- Глобальная (global)
- Разделяемая (shared)
- Константная (constant)
- Текстурная (texture)
| Тип памяти | Доступ | Уровень выделения | Скорость |
|---|---|---|---|
| register | R/W | per-thread | high |
| local | R/W | per-thread | low |
| global | R/W | per-grid | low |
| shared | R/W | per-block | high |
| constant | R/O | per-grid | high* |
| texture | R/O | per-grid | high* |
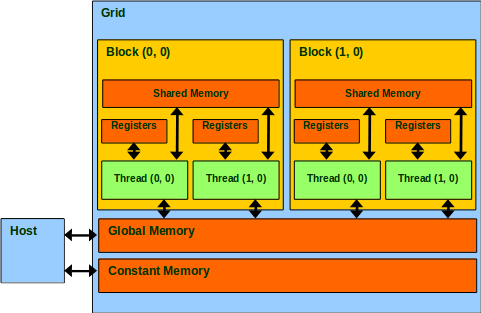
* - cashed
| Объявление переменной | Тип памяти | Уровень выделения | Lifetime |
|---|---|---|---|
| int localVar; | register | per-thread | thread |
| __device__ __shared__ int sharedVar; | shared | per-block | block |
| __device__ int globalVar; | global | per-grid | application |
| __device__ __constant__ int constVar; | constant | per-grid | application |
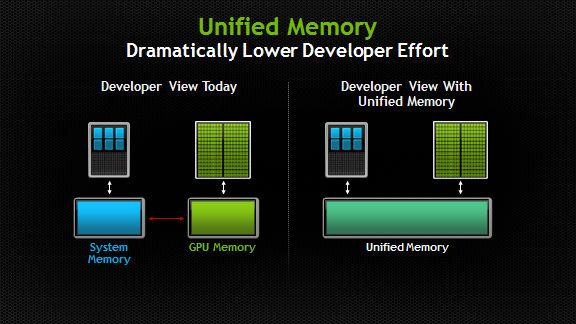
Unified Memory
доступно с CUDA 6.0
// cudaMallocManaged(void** devPtr, size_t size) - function to allocate
// unified memory, semantically similar to cudaMalloc()
// cudaDeviceSynchronize() - Wait for kernel to finish filling vals array
void sortfile(FILE *fp, int N) {
char *data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data,N,1,compare);
cudaDeviceSynchronize();
use_data(data);
cudaFree(data);
}
// __managed__ variable simplifies a program further when global variables are used.
//Read more at: http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#ixzz4PSfM1oJn
__device__ __managed__ int ret[1000];
__global__ void AplusB(int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main() {
AplusB<<< 1, 1000 >>>(10, 100);
cudaDeviceSynchronize();
for(int i=0; i<1000; i++)
printf("%d: A+B = %d\n", i, ret[i]);
return 0;
}
Преимущества Unified Memory
- Упрощенная программная и память использующая модели
- Один указатель на данные, доступный везде
- Тесная интеграция с языком программирования
- Значительное упрощение кода
- Производительность из-за локализации данных
- Доступ к данным процессора
- Гарантия глобальной согласованности
- Совместное использование с cudaMemcpyAsync()
Pinned memory
Среда runtime предоставляет функции для выделенияpage-locked (pinned) host памяти
(в сравнении с обычной pageable памятью, размещаемой при помощи malloc())
Pinned memory API
Выделение/освобождение pinned памяти
// pHost - Device pointer to allocated memory
// size - Requested allocation size in bytes
// flags - Requested properties of allocated memory
__host__ cudaError_t cudaHostAlloc ( void** pHost, size_t size, unsigned int flags )
// ptr - Host pointer to memory to page-lock
__host__ cudaError_t cudaHostRegister ( void* ptr, size_t size, unsigned int flags )
// ptr - Pointer to memory to free
__host__ cudaError_t cudaFreeHost ( void* ptr )
Преимущества
- Копирование между page-locked памятью и device памятью может осуществляться параллельно с kernel-функцией ( Asynchronous Concurrent Execution)
- Page-locked память может быть подмепирована в адресное пространство устройства, избегая дополнительного копирования с/на host/device (Mapped Memory)
- Пропускная способность между pinned памятью и памятью устройства бытрее "обычной" (для front-side bus устройств)
CUDA Потоки
CUDA streams
Поток (stream) – логическая последовательность зависимых асинхронных операций, независимая от операций в других потоках.CUDA Потоки
Шаблон
- Асинхронное копирование с host на device
- Асинхронный запуск kernel-function
- Асинхронное копирование с device на host
- Использование pinned памяти
CUDA streams API
// Create an asynchronous stream.
__host__ cudaError_t cudaStreamCreate ( cudaStream_t* pStream )
// Allocates page-locked memory on the host. (C API)
__host__ cudaError_t cudaMallocHost ( void** ptr, size_t size )
// Copies data between host and device.
__host__ __device__ cudaError_t cudaMemcpyAsync ( void* dst, const void* src, size_t count,
cudaMemcpyKind kind, cudaStream_t stream = 0 )
// Destroys and cleans up an asynchronous stream.
__host__ __device__ cudaError_t cudaStreamDestroy ( cudaStream_t stream )
// Wait for compute device to finish.
__host__ __device__ cudaError_t cudaDeviceSynchronize ( void )
// Создание CUDA streams
cudaStream_t streams[2];
for (int i=0; i<2; ++i)
cudaStreamCreate(&streams[i]);
// Выделение pinned памяти
unsigned int mem_size = sizeof (float) * size;
float *hostPtr;
cudaMallocHost ((void**) &hostPtr, 2*mem_size);
float *devPtr, *outputDevPtr;
cudaMalloc((void**) &devPtr, 2*mem_size);
cudaMalloc((void**) &outputDevPtr, 2*mem_size);
// Заполнение массива hostPtr
// {...}
// Асинхронное копирование hostPtr
for (int i=0; i<2; ++i)
cudaMemcpyAsync(devPtr + i*size, hostPtr + i*size, mem_size,
cudaMemcpyHostToDevice, streams[i]);
// Обработка на device
for (int i=0; i<2; ++i)
kernel<<< 100, 512, 0, streams[i] >>>(outputDevPtr + i*size, devPtr + i*size, size);
// Асинхронное копирование на hostPtr
for (int i=0; i<2; ++i)
cudaMemcpyAsync(hostPtr + i*size, outputDevPtr + i*size, mem_size,
cudaMemcpyDeviceToHost, streams[i]);
// Синхронизация CUDA streams
cudaDeviceSynchronize();
// Уничтожение потоков
for (int i=0; i<2; ++i)
cudaStreamDestroy(&streams[i])
Лабораторная работа
Сравнение производительности
Шаблон
Device code
__global__ void kernel(float *dA, float *dB, float *dC, int size)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < size) dC[i] = dA[i] + dB[i];
}
Шаблон
Host code
int main()
{
float timerVlueCPU, timerValueGPU;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// TODO: объявление необходимых переменных.
// размеры сетки установить равными значениям из предыдущей лекции
// старт таймера
cudaEventRecord(start, 0);
// копирование массивов
cudaMemcpy(dA, hA, mem_size, cudaMemcpyHostToDevice);
cudaMemcpy(dB, hB, mem_size, cudaMemcpyHostToDevice);
kernel <<< N_blocks, N_threads >>>(dA, dB, dC, size);
cudaMemcpy(hC, dC, mem_size, cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&timerValueGPU, start, stop);
printf("GPU time: %f ms\n", timerValueGPU);
// TODO: Аналогично для CPU
// {...}
printf("\n Rate: %f x\n", timerVlueCPU/timerValueGPU);
// TODO: освобождение памяти на host и device
// {...}
// уничтожение переменных событий
cudaEventDestroy(start);
cudaEventDestroy(stop);
return 0;
}
- Что не так?
- Замерьте только время выполнения kernel функции
- Измените функцию на более сложную
- Замерьте время с работой над памятью
- Используйте pinned память