NVIDIA CUDA
Массивно-параллельные вычисления на GPU
архитектура и программная среда CUDA
Лекция 2
Основы CUDA
Created by Vladimir Kuznetsov / @grandrust
Содержание
- Программная модель CUDA
- Гибридная модель программного кода
- Thread, block, grid blocks
- Kernel - функция
- Пример
Compute
Unified
Device
Architecture

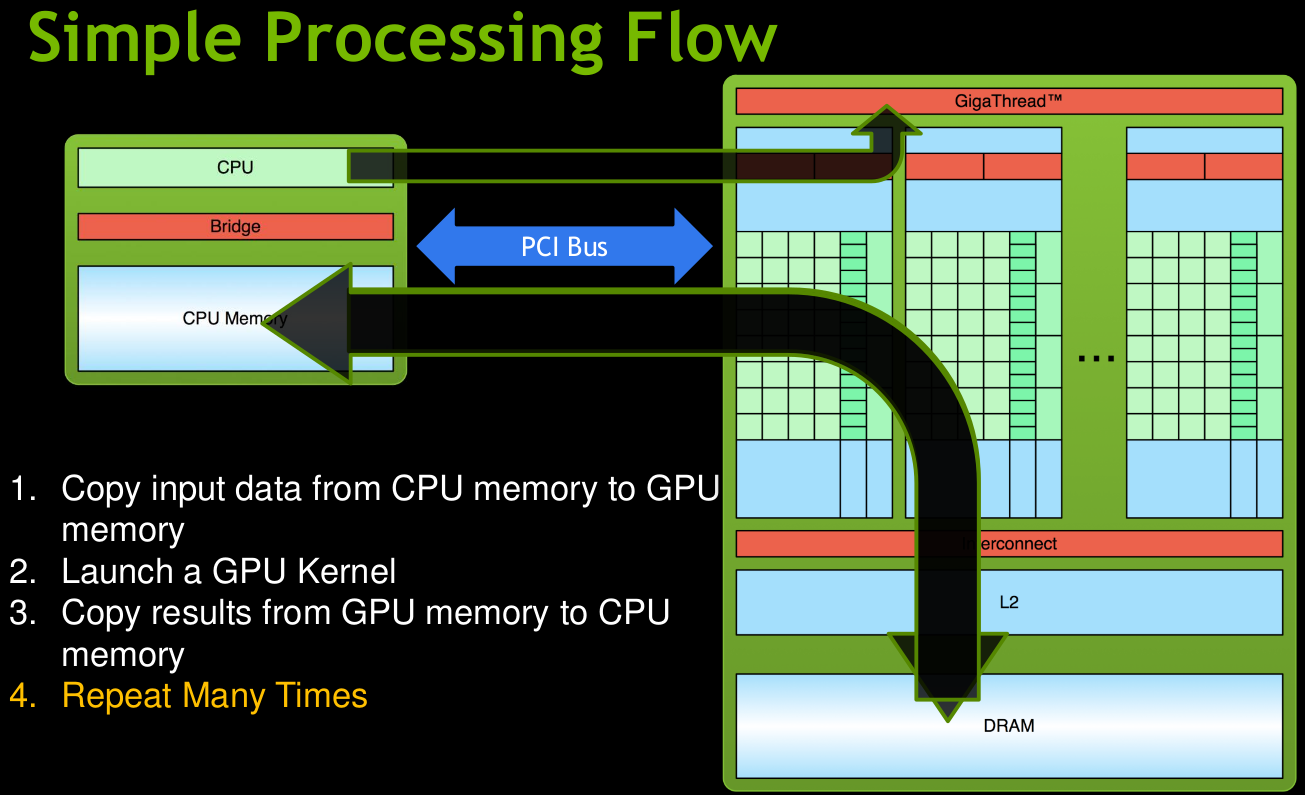
Что нужно?
- Желание
- Nvidia card
- Nvidia driver
- NVIDIA CUDA Toolkit
- Документация
- NVIDIA Nsight*
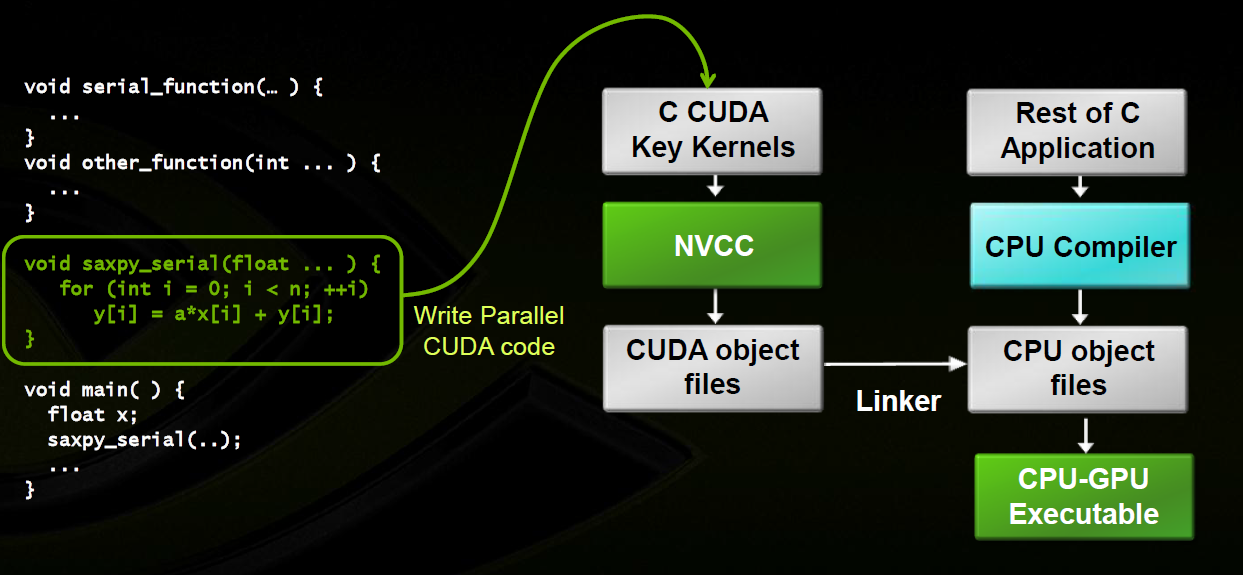
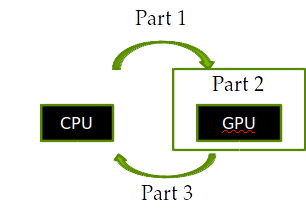
Гибридная модель
Терминология:


Структура кода
Последовательный код 
Параллельное ядро
Последовательный код
Параллельное ядро
Сборка
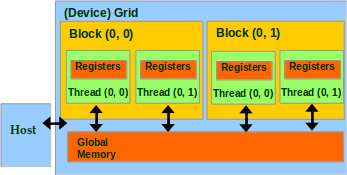
Потоки и блоки потоков
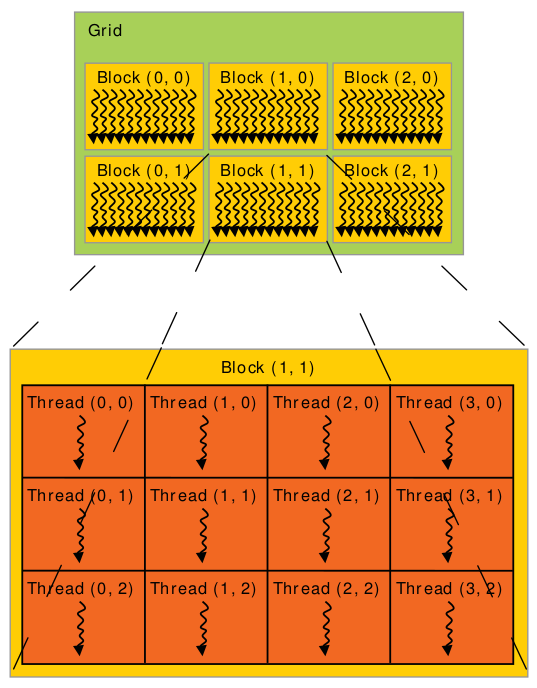
Встроенные переменные
- threadIdx: 1D, 2D, or 3D
- blockIdx: 1D, 2D, or 3D (CUDA 4.0)
- blockDim: 1D, 2D, or 3D
- gridDim: 1D, 2D, or 3D
dim3 grid(10, 1, 1)
dim3 block(16, 16, 1)
// или
dim3 grid(10);
dim3 block(16, 16);
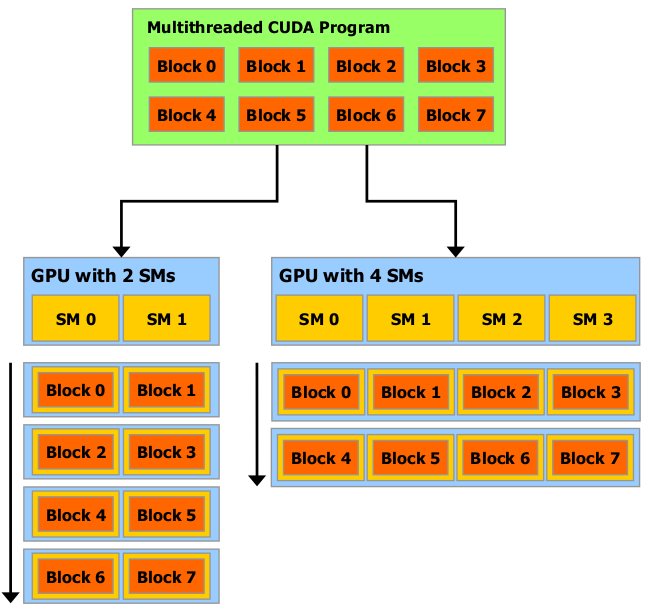
Автоматическая масштабируемость
Функция - ядро
(Kernel - function)
kernel <<< nB, nT[, nSM[, nS]] >>> (args*)
// nB: int | dim3 - число блоков в grid
// nT: int | dim3 - число нитей в block'e
Спецификаторы
| Выполняется на | Может вызываться из | |
|---|---|---|
| __device__ | device | device |
| __global__ | device | host, device* (cc >= 3.5) |
| __host__ | host | host |
Функции для работы с памятью
Выделение / освобождение памяти
cudaMalloc(addr, size)
// Allocates an object in the device global memory
// addr: Address of a pointer to the allocated object
// size: Size of allocated object in terms of bytes
cudaFree(ptr)
// Frees object from device global memory
// ptr: Pointer to freed object
Копирование памяти
cudaMemcpy(d_ptr, h_ptr, size, type)
// memory data transfer
// d_ptr: Pointer to destination
// h_ptr: Pointer to source
// size: Number of bytes copied
// type: Type/Direction of transfer (cudaMemcpyHostToDevice | cudaMemcpyDeviceToHost)
Пример
Параллельное вычисление функции
y[i] = sin(sqrt(x[i])), i = 1..N, xi = 2*Pi*i/N
N = 1024 * 1024
512 нитей в блоке,
x - количество блоков???
Device code
#include <stdio.h>
#define N (1024*1024)
__global__ void kernel(float *dA)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
float x = 2.0f * 3.1415926f * (float) idx / (float) N;
dA[idx] = sinf(sqrt(x));
}
Host code
int main()
{
float *hA, *dA;
int size = N * sizeof(float);
hA = (float*) malloc(size);
cudaMalloc((void**)&dA, size);
kernel <<< N/512, 512 >>> (dA);
cudaMemcpy(dA, hA, N * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++)
printf("a[%d] = %.5f\n", i, hA[i]);
free(hA);
cudaFree(dA);
return 0;
}
Проверка ошибок
cudaError_t err = cudaMalloc((void **) &dA, size);
if (err != cudaSuccess) {
// ......
}