NVIDIA CUDA
Массивно-параллельные вычисления на GPU
архитектура и программная среда CUDA
Лекция 1
Введение
Created by Vladimir Kuznetsov / @grandrust
Содержание
- Обзор
- Гибридная модель вычислений
- Типы вычислительных архитектур
- Архитектура GPU
- CUDA. Первый взгляд
Зачем использовать параллельные вычисления?
Цель
Увеличение скорости вычислений
=>
Увеличение тактовой частоты
Недостатки или проблемы CPU
Рост тактовой частоты ограничен
- Энерговыделение ~ второй степени частоты
- Ограничение техпроцесса
Решение - производство многоядерных процессоров
Действительно ли GPU быстрее CPU?

Сравнение CPU и GPU
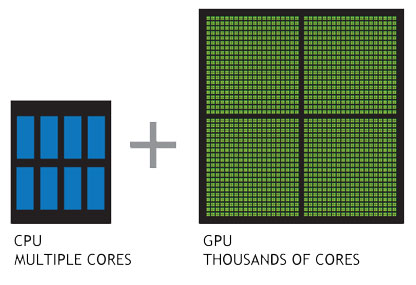
CPU
is Latency Oriented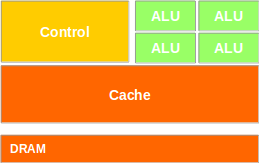
– Powerful ALU
– Large caches
– Sophisticated control
GPU
is Throughput Oriented
- Small caches
– Simple control
– Energy efficient ALUs
– Require massive number of
threads to tolerate latencies
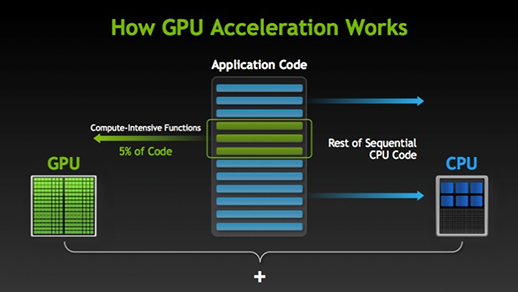
Гибридная модель вычислений
(Heterogeneous Parallel Computing)
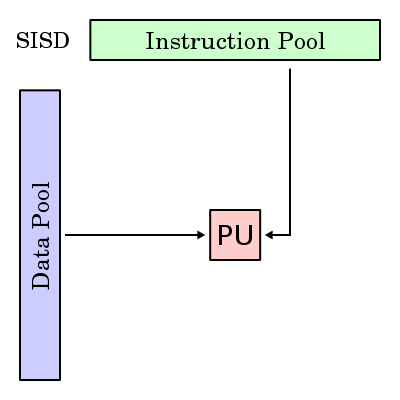
Типы вычислительных архитектур
| Single Instruction | Multiple Instruction | |
|---|---|---|
| Single Data | SISD | MISD |
| Multiple Data | SIMD | MIMD |
SISD
SIMD
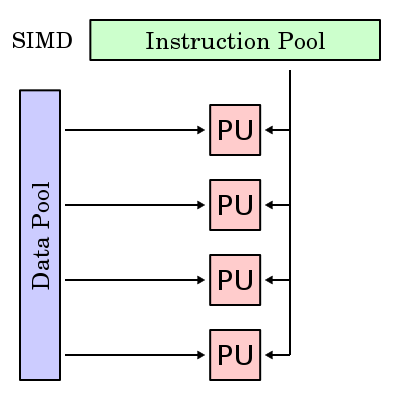
MISD
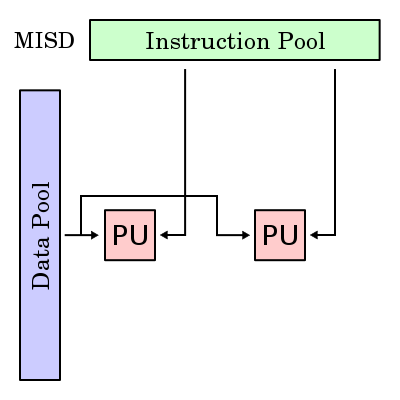
MIMD
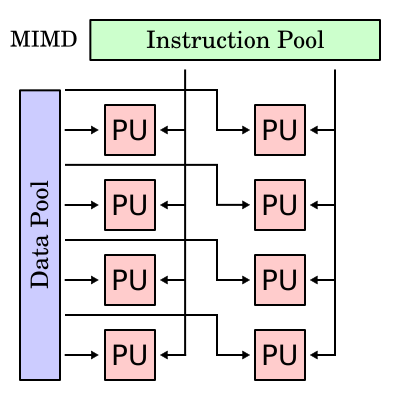
Kepler GK110

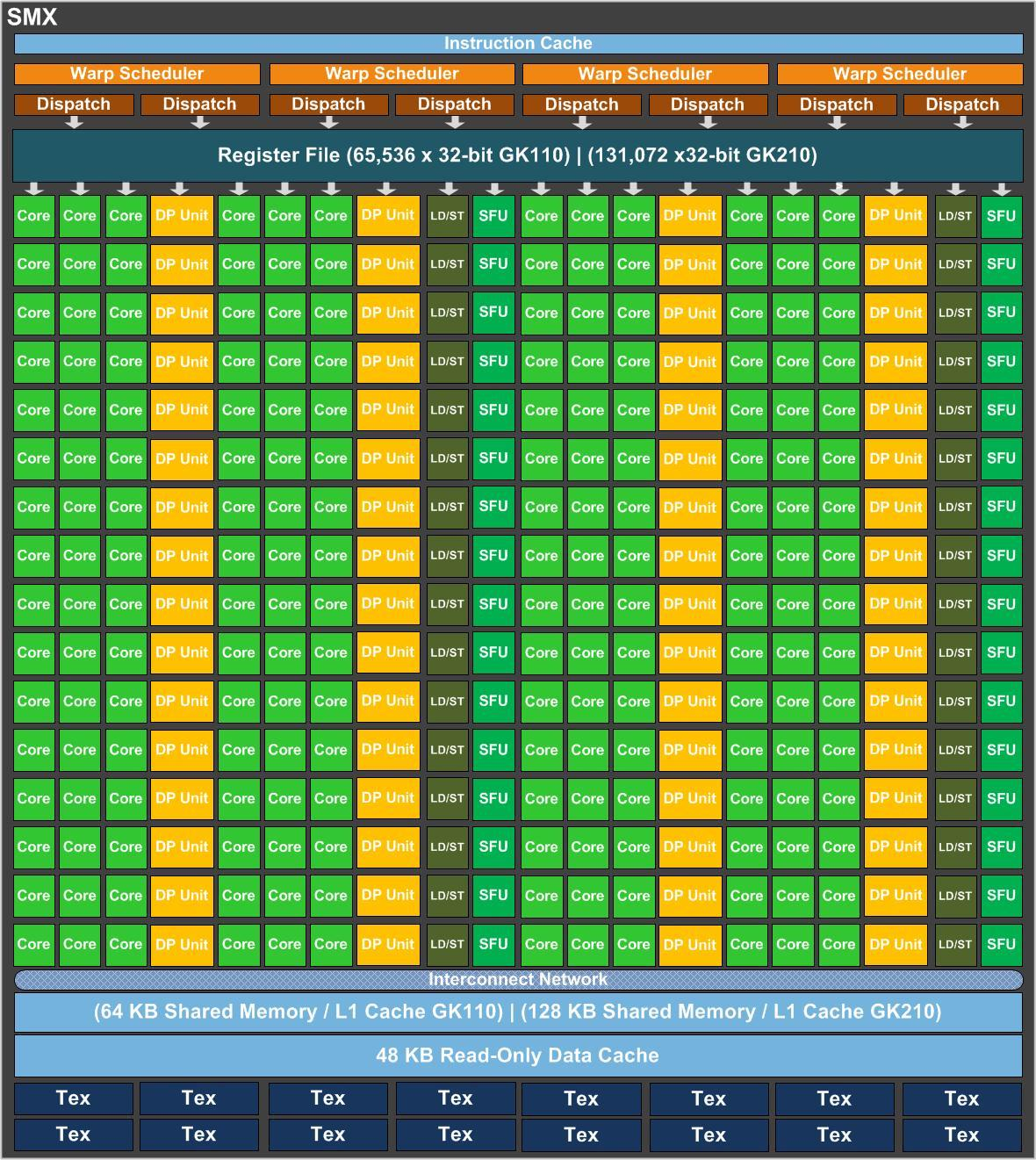
Архитектура потокового мультипроцессора (SMX)
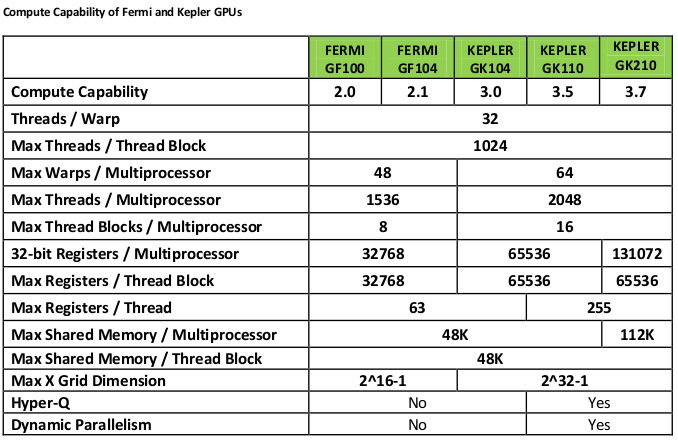
Compute Capability
Мотивация
Hello, World!
__global__ void kernel( void ) {
}
int main( void ) {
kernel<<<1,1>>>();
printf( "Hello, World!\n" );
return 0;
}
Device props
#include <stdio.h>
void printDevProp(cudaDeviceProp devProp)
{
printf("Major revision number: %d\n", devProp.major);
printf("Minor revision number: %d\n", devProp.minor);
printf("Name: %s\n", devProp.name);
printf("Total global memory: %lu\n", devProp.totalGlobalMem);
printf("Total shared memory per block: %lu\n", devProp.sharedMemPerBlock);
printf("Total registers per block: %d\n", devProp.regsPerBlock);
printf("Warp size: %d\n", devProp.warpSize);
printf("Maximum memory pitch: %lu\n", devProp.memPitch);
printf("Maximum threads per block: %d\n", devProp.maxThreadsPerBlock);
for (int i = 0; i < 3; ++i)
printf("Maximum dimension %d of block: %d\n", i, devProp.maxThreadsDim[i]);
for (int i = 0; i < 3; ++i)
printf("Maximum dimension %d of grid: %d\n", i, devProp.maxGridSize[i]);
printf("Clock rate: %d\n", devProp.clockRate);
printf("Total constant memory: %lu\n", devProp.totalConstMem);
printf("Texture alignment: %lu\n", devProp.textureAlignment);
printf("Concurrent copy and execution: %s\n", (devProp.deviceOverlap ? "Yes" : "No"));
printf("Number of multiprocessors: %d\n", devProp.multiProcessorCount);
printf("Kernel execution timeout: %s\n", (devProp.kernelExecTimeoutEnabled ?"Yes" : "No"));
return;
}
int main()
{
int devCount;
cudaGetDeviceCount(&devCount);
printf("CUDA Device Query...\n");
printf("There are %d CUDA devices.\n", devCount);
for (int i = 0; i < devCount; ++i)
{
// Get device properties
printf("\nCUDA Device #%d\n", i);
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, i);
printDevProp(devProp);
}
return 0;
}